
摘要:面对面的进行沟通交流,在我们日常人与人之间的交往中扮演着很重要的角色,从交谈者的面部我们可以获取许多我们在文字交流中难以获取的信息,例如一个人的心理状态、情绪、意向等。的确,一个人的面部蕴含着许多潜在有价值的信息,对其加以有效地收集和分析,就可以创造出一些有利用价值的数据。近些年,对于面部表情识别的研究,被广泛地应用于教育、心理、医学以及商业等多个领域,人脸表情识别也是当前计算机视觉、模式识别等多个人工智能领域的热门研究课题,它是实现智能人机交互中重要的一个环节。
深度学习,是一个近十年来飞速发展的领域,它的出现改进了许多现有的机器学习算法。在特征提取和数学建模上,深度学习都有着明显的优势,由于拥有良好的泛化能力,困扰过去人工智能领域发展的一些难以解决的问题被较好的克服了,并且随着近些年GPU数据处理能力的飞速提升,深度学习也被广泛的应用于目标检测、计算机视觉、自然语言处理等多个领域并取得了不错的成效。
本课题主要针对旅游景区这一特定应用场景,实现利用多任务卷积神经网络(MTCNN)模型实现对游客人脸的实时检测,再利用一个简化的AlexNet卷积神经网络模型实现对所检测到的人脸进行表情分类。经过多次的模型训练和改良,最终在CPU环境下可以实现到一个不错的实时检测效果。
Abstract: Face-to-face communication plays an important role in our daily interpersonal interactions. From the face of the interlocutor, we can obtain a lot of information that we cannot obtain in text communication, such as a person’s mental state, emotions, and intentions, etc. Indeed, faces contain a lot of potentially valuable information. An effective collection and analysis of them can create some valuable data. In recent years, research on facial expression recognition has been widely used in education, psychology, medicine, and business. Facial expression recognition is also popular research in the community of artificial intelligence such as computer vision and pattern recognition. It is a critical component in the realization of intelligent human-computer interaction.
Deep learning is a rapid development field over the past decade, and its emergence has improved many existing machine learning algorithms. In feature extraction and mathematical modelling, deep learning has obvious advantages. Due to its good generalization ability, some intractable problems that have troubled the development of artificial intelligence in the past have been better overcome. In recent years, with the rapid development of GPU data processing capabilities, deep learning has also been widely used in target detection, computer vision, natural language processing and other fields and has achieved good results.
This subject is mainly aimed at the specific application scenario of tourist scenic spots, using the multi-task convolutional neural network (MTCNN) model to realize the real-time detection of tourist’s faces, and then a simplified AlexNet convolutional neural network model is used to realize the classification of the detected faces. After many times of model training and improvement, a good real-time detection result can be achieved in the CPU environment.
1. 绪论
本章节重点介绍基于深度学习的景区游客笑脸识别与实现这一课题的研究背景和意义,国内外目前针对人脸检测、表情识别等研究方向的研究成果以及遇到的一些难题。本章节还将对实现本课题的具体步骤初步进行简要概述,并对本文的结构框架作出阐述。
1.1 课题的背景和意义
心理学研究表明,人脸表情是人类表达情感的重要载体之一,其中蕴涵着丰富的人体行为信息,通过一个人的表情,就可以预测此时此刻这个人内心的情感、动机、个性等众多信息。由此可见,对表情的理解是智能的体现,如果计算机可以智能地对这些人脸表情信息进行收集并加以分辨,将从根本上改变人机交互的方式,使计算机更好的服务于人类。
随着近些年数据量的爆炸式增长,大数据技术也在迅猛地发展,在商业、经济以及其他领域中,决策将日益趋向于由数据和分析而作出,而并非基于传统习惯上的经验和直觉。大数据能够为企业改进运营模式提供强有力参考,也可为用户带来更为丰富的服务体验,而如今在高效的算法和成熟计算能力的硬件的加持下,深度学习被应用在了我们生活的方方面面。而人脸作为一个可以传递思想感情的一种重要方式,近些年对人脸的各种研究也是不断地被开展并且研究成果被广泛的应用于各种领域。然而目前在国内,机器学习技术在旅游业的应用仍然处于发展的初级阶段,国内大部分智慧旅游及旅游大数据企业仍然以提供信息化基础建设及旅游大数据的可视化为主,缺乏真正的机器学习以及人工智能的技术实现。目前,国内仅有少数为旅游者和旅游管理部门提供智能化服务的企业,这些企业率先应用了机器学习技术,从而进一步提升了行业管理水平,优化游客旅游服务体验。在旅游管理方面,对于机器学习技术的应用可以促进旅游产业监管检测以及强化景区内部管理制度,从而提升旅游业管理人员的决策能力以及管理效率。
经过多年研究的发展,围绕人脸表情识别的研究已经数不胜数,来自全世界不同地方的研究者们也先后提出了很多优秀的方法。近些年,由于深度学习具有无监督特征学习能力突出的优点,所以对之的应用也是越来越多。本课题就针对旅游业这一特定行业,利用一些现有的技术手段,实现对旅游景区游客人脸的检测以及表情识别,从而可以协助景区管理者更及时的调整运营模式,为游客提供更好的服务和出游体验。
1.2 国内外目前对于人脸检测、人脸表情的研究现状
从19世纪起,人类就开始了对于人脸表情的研究,但是提及人脸表情,就不可避免的会涉及到人脸检测的问题,因为对于计算机而言,需要先从大维度的图像数据中完成对人脸位置的定位和裁切,才能进一步实现对人脸表情的分类。所以,本节将针对人脸检测、人脸表情现如今国内外的主要研究现状作出概括并总结研究中遇到的一些主要问题。
1.2.1 人脸检测
人脸检测是计算机视觉中一个被广泛研究的课题,如今大多数人脸检测器都可以轻松的实现正面人脸的检测任务,对于该领域的最新研究更多地集中在不受控制的面部检测问题上1,例如姿势变化,夸张的表情和极端照明等许多可能导致面部外观出现较大的视觉变化的因素,这些因素可能会严重地降低面部检测器的耐用性。
人脸检测任务的困难主要源自两个方面:1)在杂乱的背景中,人脸的视觉变化会很大; 2)在大范围内搜索各种各样的人脸尺寸和姿势。前一种要求人脸检测器能准确地解决二分类问题,而后一种则进一步要求检测器需要提高检测效率。
最开始Viola-Jones是使用Haar特征来实现面部检测器的2,使用这个特征可以对相对正向的面部完成迅速评估并识别。然而,由于Haar特征的简单特质,在不受控的环境中使用它进行人脸检测相对较弱,例如各种各样的人脸的姿势或不理想的光照条件。在过去的十年中,研究者们提出了很多基于Viola-Jones的人脸检测器的改进3,这些改进大部分是基于更先进的特征的级联式框架,得力于更优秀的特征,这些改进可以实现准确度更高的二分类任务,而且总体上对于计算量的需求并没有提高。但近些年随着硬件条件的不断进步,卷积神经网络在图像分类任务中取得了质的飞跃,也很快被应用于人脸检测的任务中,其性能和精度都超过了之前基于特征的检测方法。在第二章中,将对一些基于深度学习方法的人脸检测算法进行阐述和总结。
1.2.2 人脸表情
人通过变化自身的脸部肌肉以及眼和口部的肌肉,从而形成各种各样的表情,这些表情可以被用来传达不同的情绪状态,与声音、语言和身体语言等组成了人的交流系统中沟通系统。人脸面部表情识别是一个横跨众多科研领域的课题,例如神经学、人工智能领域等,当然对于该项课题的研究成果也被应用于广泛的领域,例如对病人进行心理测评、潜在用户购买行为的预测等4。
对于人脸表情的研究的先锋者是Darwin5,之后Ekman和Friesen提出了面部运动编码系统(FACS)6,FACS是一种基于人类观察者的系统,旨在促进客观测量由面部肌肉收缩引起的面部外观的细微变化。通过对44个面部动作单元的监控,FACS可以对所有明显可辨别的表达方式进行语言描述。这个系统还定义了六种普遍公认的基本的人脸表情,分别是:开心、伤心、惊喜、害怕、生气和厌恶。尽管这六种表情是否是通用的人脸表情受到了很多人的质疑,但是之后大多数基于视觉的面部研究都是依赖于Ekman的定义的表情分类开展的,所以说FACS系统的提出是具有里程碑意义的。
使用计算机对人脸表情信息进行特征提取,并且按照人类的思维方式对其加以理解和归类,再使用人类对表情已有的认知使计算机对检测到人脸表情加以联想,就是我们所说的人脸表情自动识别系统。人脸表情自动识别系统可以被应用于人机交互、压力监测、人类行为分析等众多领域,所以对于开发一套完整的人脸表情识别系统的研究吸引了来自不同领域的研究者。总体来说,对于人脸表情识别的方法可以被粗略的分为两种:基于几何特征的方法和基于外观的方法7。基于几何特征的方法依赖于人脸特征的几何分布,例如眉毛、眼睛、眼角、鼻子、嘴巴等脸部元素的位置和形状,但是试验结果表明,由于图像的质量、照明的情况等一些不可控的因素,用基于人脸几何特征分布的方法预测人脸表情并不是很可靠;至于第二种方法,基于外观的方法,是采用光流法或某些特定的滤波器对整个人脸或人脸的局部进行分析。
人脸表情识别大致可以分为以下几个部分:图像的采集,图像数据的预处理,人脸检测,人脸特征提取,最终获得表情所属的分类。图1给出来表情识别的具体过程。
 图1 表情识别过程
图1 表情识别过程
1.3 本课题的内容阐述
本课题主要模拟旅游景区这一特定应用场景,先后分别训练出一套可用的人脸检测神经网络模型和一套负责完成表情分类的网络模型,将两个模型进行融合。之后完成对包含人脸的图像以及视频数据的采集,完成对采集的图像以及视频数据进行预处理后,输送进训练好并融合在一起的神经网络,使用模型实现对数据中人脸的定位以及预测表情的所属分类。
实现本课题具体流程如下: (1) 选取训练数据集 实现训练本课题所用卷积神经网络模型,一共要用到三套数据集,分别用来训练人脸检测模型、人脸关键点回归以及边框回归、和表情分类的模型。 (2) 神经网络的搭建 如上述所示,一共需要两个不同的网络模型。用于实现人脸检测的模型我采用了多任务卷积神经网络(MTCNN),该网络可以同时实现人脸的检测与对齐,同时完成人脸关键点定位。用于人脸表情分类的网络,我采用了经典的AlexNet结构8,但将其特征维度进行了调整,从原始的千分类网络降成7分类网络。 (3) 网络训练 使用的深度学习框架Caffe,完成对神经网络的搭建和训练,Caffe框架对于简单模型的建立和训练,对于刚刚接触深度学习的人更加友好且更加便捷。并且Caffe拥有python和matlab的接口,可以方便的搭配利用opencv对图像进行处理。 (4) 测试以及模型完善 在网络训练结束后,就可以用建立好的网络模型,在实际的应用场景下进行测试,检测理论是否符合实际,及时发现问题并尽量完成对网络模型的修正。
1.4 本文的组织结构
第一章 绪论。主要对开展本课题的研究背景进行介绍,说明研究此课题的目的和意义,简单总结当前国内外针对人脸检测和人脸表情检测研究的主攻方向和方法,并简单介绍对于本课题的主要内容和实现步骤以及使用方法,概括本文的章节安排。
第二章 深度学习的基本原理。本文重点使用的方法都是基于卷积神经网络来完成对数据特征的提取的,从而可以进一步实现分类任务。本章将简要对卷积神经网络的原理和结构进行阐述。为了能够准确且实时的从给定图像或视频数据中完成对人脸的检测和表情的识别,人脸检测的任务显得尤为重要,所以一个好的人脸检测模型是不可或缺地。本章进而将重点介绍多任务卷积神经网络理论,以及在具体实现人脸检测任务时涉及到的方法或算法。
第三章 人脸检测及人脸表情识别网络结构。本章主要对人脸检测、人脸表情识别的卷积神经网络进行讨论,将详细阐述所用网络架构和训练方法。
第四章 实验与测试。根据研究的课题,实验步骤可被分为四步:(1)训练数据集的选取;(2)神经网络模型的搭建及训练;(3)实际任务下的检测和对模型的修正。本章主要记录用卷积神经网络实现人脸表情识别系统的过程并实际测试使用效果。
2. 深度学习的基本原理
2.1 引言
机器学习技术为现代社会的各个方面提供了强大的动力:从网络搜索到社交网络上的内容过滤再到电子商务网站上的推荐机制,并且它在诸如相机和智能手机之类的消费产品中越来越频繁地被利用。然而常规的机器学习技术在处理原始格式的自然数据方面受到了限制。几十年来,想要构建一个模式识别或者机器学习系统,需要非常仔细的工程设计和相当多领域的专业知识,才能设计出一个可以从输入中检测或分类其模式的子学习系统。表征学习是一组允许向机器提供原始数据并可以自动发现需要被检测或分类的表征的方法。深度学习方法是具有多层表征的表征学习方法,这些层级是通过组合简单但非线性的模块而获得的,每个模块将一个层级(从原始输入开始)的表征转换为更高且稍微更加抽象的层级的表征。有了足够多的此类转换,非常复杂的函数模型也可以被学习了。事实证明,深度学习方法非常善于发现高维数据中的复杂结构,因此在科研,商业和政府等众多领域都是适用的。
深层神经网络是目前主要的深度学习形式,卷积神经网络就是其中一种经典的结构。卷积神经网络是被设计用来处理多维数组数据的,比如一张包含三个由三颜色通道组成的二维像素值的彩色图像。卷积神经网络使用4个关键的思想来利用自然信号的属性:局部连接、权值共享、池化以及多网络层的使用9。本章将简要概括卷积神经网络的结构和基本原理,并重点介绍一下本文人脸检测所用的算法 – 多任务卷积神经网络(MTCNN)。
2.2 卷积神经网络
一个典型的卷积神经网络(CNN)的结构可以被分为几个部分,如图2所示。最前面的部分是由卷积层和池化层两种层级结构构成。卷积层含有多个特征图(Feature Map),这些特征图则是由神经元组成,每一个单独的神经元通过卷积核与当前特征图之前的特征图的局部相连接,这里的卷积核是一组由权值组成的矩阵,而这个链接的局部可以被称为局部感受野。这里得到的局部加权和将被通过一次非线性函数的运算,例如修正线性单元(ReLU函数),之后将得到该卷积层中所有神经元的输出值。在同一特征图中,所有的神经元共享相同的卷积核,该特性也被称为权值共享,但在不同的特征图中,所用的卷积核是不同的。通过权值共享操作,可以有效的降低模型复杂度,并可以更快捷地训练网络。使用这种结构的原因有两个:第一,对于一个阵列数据,例如图像,局部的一些数据是具有高度相关性的,一个可辨别的图案是由一个区域内的所有数据形成的而并非某一点的一个数据;第二,在例如图像这种数据中,局部的数据是和其位置无关的,例如人脸可能会出现在一张图像中的任意位置。在数学意义上,这里的卷积核操作就是一个离散的卷积操作,卷积神经网络也因此而得名。
在卷积层之后,紧接着的是池化层,和卷积层结构类似,由池化操作得到的每一个特征图都唯一对应其之前层的某一个局部感受野。如果说卷积层的作用是用来检测上一层中局部特征的,那么池化层扮演的角色则是融合前面检测到的相似的特征。由于组成某一图案的特征是可变的,所以为了提高模型的泛化能力和鲁棒性,对之前提取到的特征图进行压缩处理是很有必要的,这么做同时还可以降低模型的复杂度,提高训练速度。常用的池化操作包括最大池化、均值池化等,分别对其对应的局部感受野进行求最大值或均值,至于在不同应用场景下应该应用哪些池化操作,Boureau等人10做出了详尽的理论分析。
经过几个卷积层和池化层的反复操作后,在CNN结构中一般还会有1个或以上的全连接层。与传统的神经网路类似,CNN中的全连接层中的单个神经元会与其前一层的所有神经元一一对应相连,通过全连接层后,之前经过卷积层和池化层后得到的区分性局部信息将被得到整合。如果想要提升整个网络结构的性能,可以在全连接层中的每个神经元后加一个非线性函数(例如ReLU函数)以提高其非线性分类能力。通过最后一层全连接层后,将得到输出值,这些值形成输出层,该层可以通过采用例如softmax逻辑回归的方法进行分类任务。最后通过计算一个损失函数,就可以开始使用反向传播算法进行特征值的迭代训练了。
当然,本文只是简单对卷积神经网络的原理和结构进行了概述,很有很多细节例如特征图维度和数量的选取、损失函数的选取、正则化方法等都没有进行总结,由于其内容过于冗长,所以仅对一些必要的内容进行了阐述。 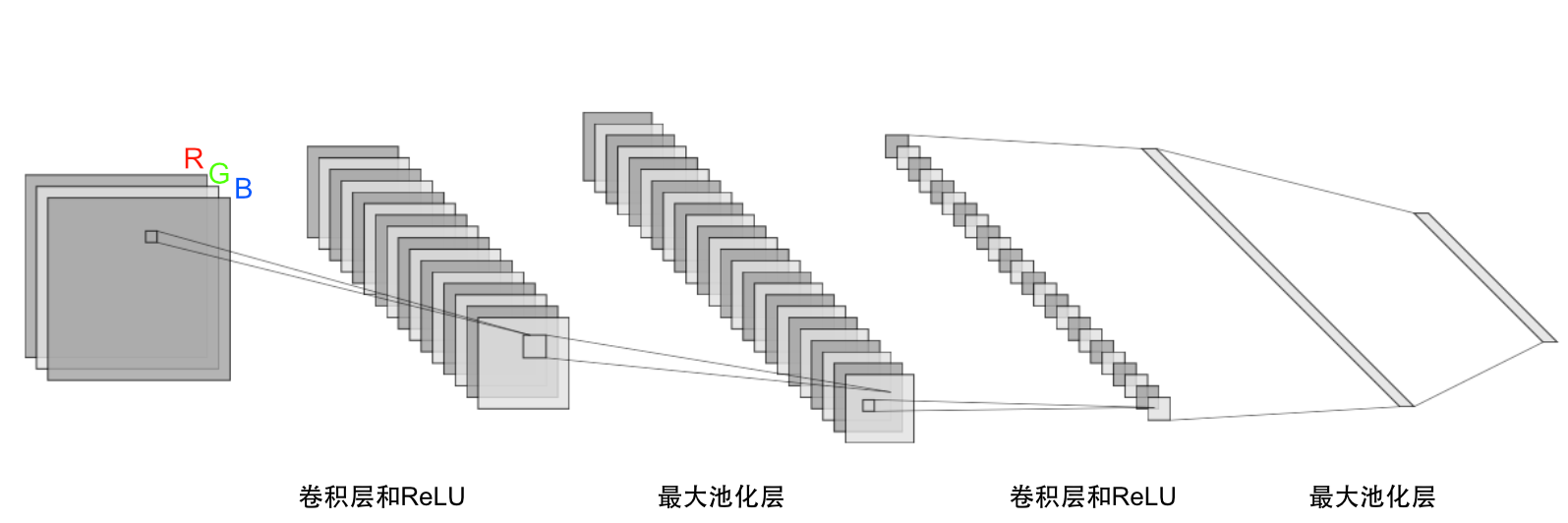 图2 卷积神经网络的基本结构
图2 卷积神经网络的基本结构
2.3 人脸检测算法
2.3.1 人脸检测算法概述
人脸检测的目标是找出输入图像中是否有人脸,如果有,需要输出所有包含人脸的对应位置,算法的输出是人脸外接矩形在图像中的坐标,可能还包括姿态如倾斜角度、五官位置等信息。在目标检测所有的子研究领域中,人脸检测是目前被研究的最充分的问题之一,它在安防监控、人机交互、社交娱乐等方面有很高的应用价值,也是整个人脸识别、表情识别等算法的第一步。
虽然人脸近似于一个刚体,都是由五官构成,但由于表情、姿态、角度、光照等原因,准确的定位图像中的人脸是有难度的。一个人脸检测算法需要考虑如下几个问题:人脸会出现在图像中的任意位置;人脸在图像中的尺寸是可变的;图像中的人脸可能是任意角度和姿态的;图像中的人脸有可能被遮挡。正确检测率和误检率两个指标通常被用来评价一个人脸检测模型的好坏,正确检测率被定义为
\[\text{正确检测率}=\frac{\text{检测到的人脸数量}}{\text{图像中所有的人脸数量}}\]误检率被定义为
\[\text{误检率}=\frac{\text{误报个数}}{\text{图像中所有非人脸扫描窗口数量}}\]一个优秀的人脸检测算法,将会在正确检测率和误检率之间进行权衡,从而获得尽可能高的正确检测率和低的误检率。一个典型的人脸分类器模型需要用大量的人脸和非人脸图像进行训练,训练后可以得到一个能够解决二分类问题的分类器模型,该分类器模型也被称为人脸检测模版。该分类器模型可以对输入图像进行预测,从而获得图中是否为人脸,但通常该分类器仅可以对固定大小的输入进行处理,所以对一般输入(非训练时设定的尺寸)的数据,需要进行如图3所示的处理。由于人脸的尺寸可以是任意的,所以第一步需要对原始输入图像进行尺寸的放大和缩小,从而构建图像金字塔;接下来为了检测所有图像金字塔内图像的任意位置的人脸,需要对所有图像进行滑动窗口(Sliding Window)检测,简单来说就是用一个固定尺寸的窗口在所有图像内进行从上到下、从左到右的滑动检测。这个过程需要对大量不同尺度的图像进行反复扫描,从而获得预选人脸窗口,所以这个过程会消耗大量时间。 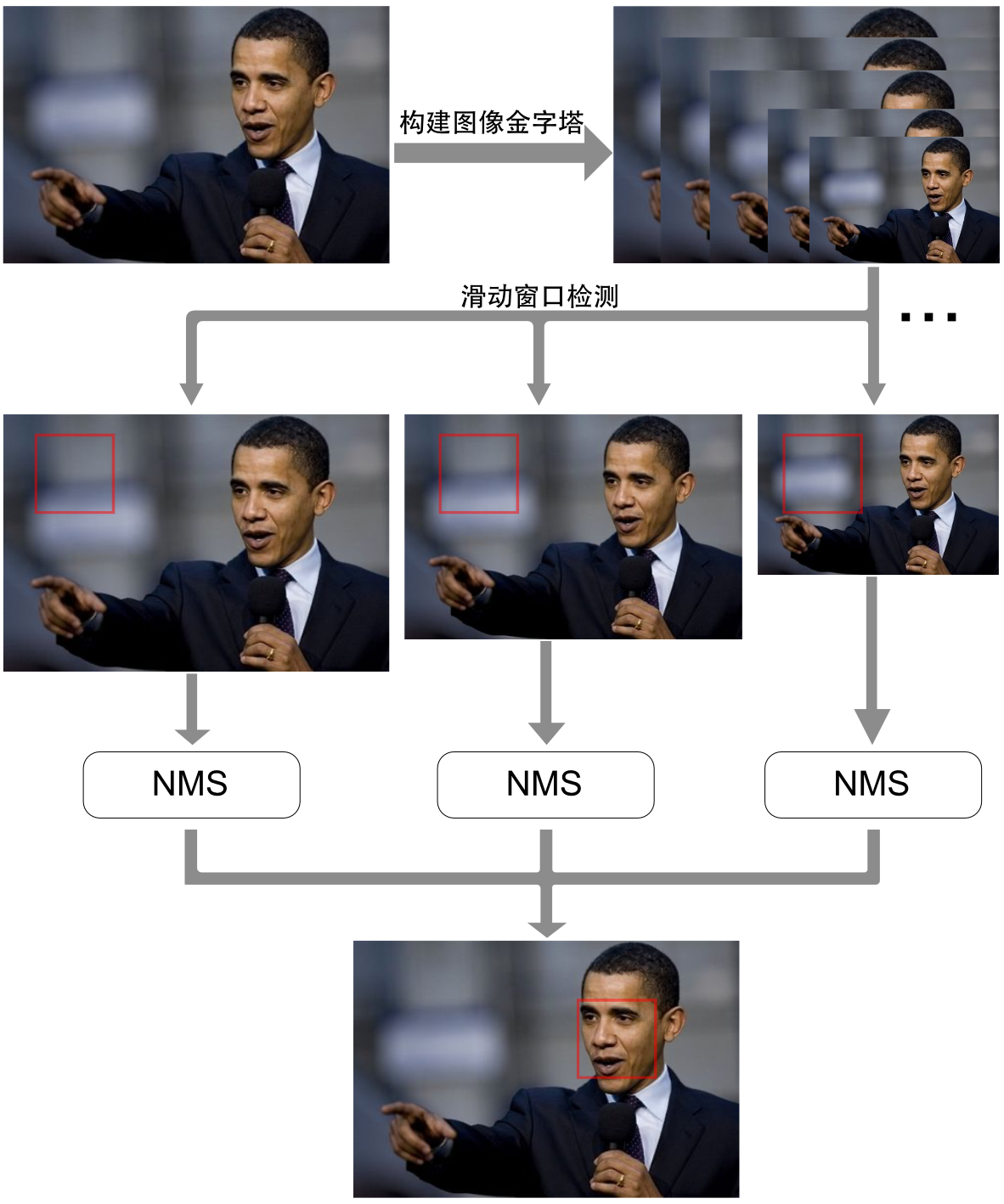 图3 多尺度滑动窗口实现人脸检测
图3 多尺度滑动窗口实现人脸检测
如图3所示,滑动窗口在完成检测后,还会进行一步非极大值抑制(NMS, Non-maximum Suppression)操作。顾名思义,该操作就是抑制局部非极大值的预测,从而保留概率最高的局部最大值。该算法不仅适用于人脸检测,在几乎所有的目标检测任务中,都会用NMS来对所有的预测窗口进行筛选。如图4,假设当前完成滑动窗口检测后,有多个人脸的预选窗口存在,可以看出这些预选窗口是高度重合的,我们的任务是将这些高度重合的预选窗口进行排序,迭代排除掉所有概率相对较低且与概率相对较高的预选窗口高度重合的预选窗口,从而保留IOU相对较低的所有高概率预选窗口。经过NMS操作后,大量的高度重合的无用预测窗口将会被筛选掉。  图4 NMS操作
图4 NMS操作
以上是对整个人脸检测流程的简单概述,基本覆盖了典型人脸检测算法的所有流程。不同的人脸检测算法,大多是基于该流程基础上,对人脸分类器进行改良,例如级联CNN算法1(Cascade CNN),该算法的人脸分类器采用的是级联式的框架。在构建完图像金字塔后,在第一层网络上(12-net)将对这些图像进行滑动窗口检测并过滤掉超过90%的预选窗口,剩下的窗口将被送入一级校准网络(12-calibration-net)进行窗口校准,并采用NMS合并高度重叠的检测窗口,在后面更高层级的网络中,将进行人脸检测框位置进一步的矫正和进一步的筛选,详细网络结构可以参考文献[1]。该算法在一定程度上降低了传统算法在开放环境中对于光照、位置、角度等的敏感度,相较于之前基于传统卷积神经网络的一些算法是有很大突破的,但是由于框架的第一级网络仍然是采用滑动窗口的形式进人脸位置的初步检测,所以在对效率要求较高的应用场景下,该算法还是被限制了,而且级联CNN模型对于小目标人脸检测仍不是很好。仍然采用类似于级联CNN算法的级联式框架,Zhang等人11在2016年提出另一种级联式的人脸检测模型–多任务卷积神经网络,本文后续在程序实现时也是采用的这种人脸检测算法,在下一小节将对这种算法进行详细阐述。
2.3.2 多任务卷积神经网络
MTCNN(Multi-task Convolutional Neural Network)顾名思义是一种集人脸分类、人脸区域回归和人脸关键点回归三个任务于一身的多任务同时执行的算法,结构采用的是类似于级联CNN算法的级联式结构,不同于级联CNN算法的是在初级的检测中没有使用滑动窗口的方法来对输入图像进行初步人脸框预测,这种算法同时兼顾了计算效率和准确率,对上述两种评测指标进行了良好的平衡。
在开始介绍MTCNN的网络结构和工作原理之前,需要先了解边框回归(Bounding-Box regression)的工作原理,这也是在MTCNN网络中在执行人脸边框预测、人脸关键点回归任务时至关重要的一个步骤。之所以要执行边框回归的操作,是为了使预测的人脸边框位置或者对于人脸关键点的定位更加准确,如图5(a)所示,在输入图像经过网络后得到的预测人脸窗口为红色框覆盖区域,而准确的人脸位置应该是绿色框所覆盖的区域,这时红色框的定位并不准确(例如 $IOU<0.7$),所以我们需要对预测窗口进行修正。对于窗口,一般使用四维向量 $(x,y,w,h)$ 分别表示窗口的中心点坐标、高度、和宽度,如图5(b)绿色框 $G$ 代表准确位置,红色框 $P$ 代表原始的预测位置,而蓝色框 $G’$ 则代表一个经过校准后更加接近于真实窗口 $G$ 的窗口区域。所以边框回归的目的就是当给定 $(P_x,P_y,P_w,P_h)$ 时,寻求一种映射 $f$ ,从而使得
\[f(P_x,P_y,P_w,P_h)=(G'_x,G'_y,G'_w,G'_h)\tag{2.1}\]并且
\[(G'_x,G'_y,G'_w,G'_h) \approx (G_x,G_y,G_w,G_h)\tag{2.2}\]至于如何修改损失函数从而使窗口 $P$ 校正成更接近准确窗口的窗口 $G’$ ,本文不做详细赘述,可以参考文献12。
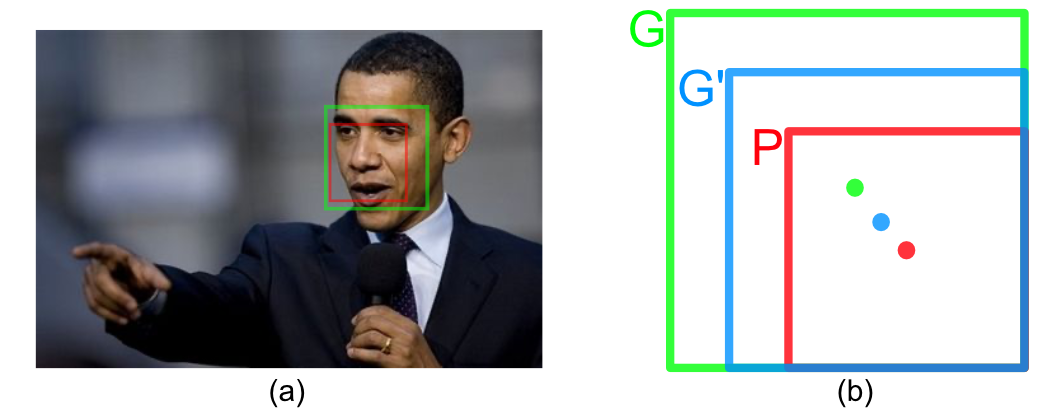 图5 边框回归原理
图5 边框回归原理
MTCNN采用了三个级联卷积神经网络级联的结构,如图6所示,分别为P-Net,R-Net,O-Net,三个网络结构从简单到复杂,采取候选框以及分类器的思想,从而可以非常高效的进行人脸检测任务。
 图6 MTCNN整体结构
图6 MTCNN整体结构
图像金字塔中图像首先会被送入P-Net(Proposal Network),顾名思义这是一个人脸区域建议网络。该网络是一个全卷积网络13,相较于上文提到的级联CNN网络第一级的12-net,P-Net使用的全卷积网络的优势在于由于在网络中没有全连接层(当然有些网络在有全连接层时也可以接受任意尺寸的图像输入,例如空间金字塔池化法14),所以它可以接受任意尺寸的图像输入,且相较于滑动窗口的方法,卷积运算可以节省大量的计算时间。P-Net是一个相对较浅的网络,而且输入特征仅为$12\times12\times3$大小,所以该网络可以快速地初步对人脸框位置以及人脸关键点进行回归。由于这个网络仅是由三个卷积层和一个最大池化层构成的神经网络,而且每层结构并不复杂,所以特征经过这一级网络后得到的预测仅仅是有一定可信度的,即使之后使用NMS和边框回归算法分别对候选框进行了筛选和校正,但是此时的预测结果仍然不准确。
第二级网络为R-Net(Refine Network),顾名思义这一级网络是用来改进前一级网络对人脸位置和关键点的回归的。相较于P-Net,R-Net多了一层全连接层,且输入特征也是增大到了$24\times24\times3$,因此这一层网络会对输入数据进行更加仔细严格的筛选,大部分的错误预测会被该级网络排除掉,之后会有同样的NMS和边框回归算法操作。之所以R-Net可以实现更加精确的预测,这得力于R-Net最后一层128大小的全连接层,这个全连接层可以保留更多的图像特征,从而实现更高的准确性。
最后一级网络被称为O-Net(Output Network),这层网络是用来进行最后一级筛选和校准并输出预测和回归结果的。O-Net是三级网络中结构最为复杂的一个,输入特征为$48\times48\times3$,相较于R-Net,O-Net多了一个卷积层,并且全连接层的维度扩大到了其两倍,这意味着它会保留更多的图像特征细节,实现更加精准的人脸判别、人脸区域回归、以及人脸特征定位。
总结来说,MTCNN利用从简易到复杂的级联式神经网络结构,兼顾了计算效率和准确率,第一级网络使用了全卷积网络从而避免了滑动窗口采样操作带来的巨大的计算时间消耗,大幅度提升了人脸框预测和关键点回归的效率。由于其简易的网络结构和相对不错的效率和准确度,MTCNN在工业级场景中得到了广泛应用。
3. 人脸检测及人脸表情识别网络结构
3.1 CNN结构
如上一章节所述,MTCNN共包含3个子网络(P-Net,R-Net,和O-Net),3个子网络通过级联的方式实现对人脸的检测、边框回归、以及人脸关键点的回归,3个网络的具体参数和机构如图7所示。  (a) P-Ne
(a) P-Ne
 (b) R-Net
(b) R-Net
 (c) O-Net
(c) O-Net
图7 MTCNN3个子网络架构(Conv代表卷积层,步长为1;Max-Pool代表最大池化层,步长为2)
用于人脸表情分类的网络,本文使用的是一个简化版的AlexNet,原始的AlexNet是用于1000类分类的维度庞大的网络,由于表情共分为7个不同类别,所以简化的网络即为一个七分类网络,结构如图8所示。  图8 人脸表情分类网络架构(Conv代表卷积层,步长为1;Max-Pool代表最大池化层,步长为2)
图8 人脸表情分类网络架构(Conv代表卷积层,步长为1;Max-Pool代表最大池化层,步长为2)
3.2 网络训练
我们在整个实现算法中,一共用到了两个模型。在MTCNN网络中共有三个任务,分别是人脸二元分类任务、边框回归、以及人脸关键点定位,所以我们需要用到三个不同的损失函数得到熟练,分别是
- 人脸二元分类任务损失函数使用的是分类任务常用的交叉熵函数,对于每一个样本$x_i$,
其中$p_i$是输入经过网络后得到是人脸的概率值,$y_i^{bin}\in{0,1}$表示已标注的真实标签。
- 边框回归(Bounding Box Regression)任务的损失函数是计算预测边框与最近真实边框的欧式距离,对于每个样本$x_i$,
其中$\hat y_i^{bbr}$是回归预测得到的边框位置,$ y_i^{bbr}$是标注框的真实位置,$ y_i^{bbr}\in\mathbb{R}^{4}$。
- 人脸关键点回归任务与边框回归任务类似,同样计算预测点与真实标注点的欧式距离,对于每个样本$x_i$,
其中$\hat y_i^{lm}$是通过网络得到的预测值,$y_i^{lm}$是真实的标注值,$ y_i^{lm}\in\mathbb{R}^{10}$。
由于我们在MTCNN的三个不同CNN中需要完成不同的任务,所以在训练时,输入的训练数据也是不同的,因此在训练不同的CNN时计算的损失函数也需要区别对待。总的训练损失函数可以表示为
\[\sum_{i=1}^N \sum_{j \in \left\{bin,bbr,lm \right\} }{\alpha_j \beta_i^j L_i^j}\tag{3.4}\]其中$N$表示训练样本总数,$\alpha_j$表示任务权重,在P-Net和R-Net中,$\alpha_{bin}=1,\alpha_{bbr}=0.5,\alpha_{lm}=0.5$,在O-Net中$\alpha_{bin}=1,\alpha_{bbr}=0.5,\alpha_{lm}=1$,$\beta_i^j\in{0,1}$表示样本类型权重。
对于人脸表情识别网络,它是一个多分类网络,所以损失函数使用的同样是交叉熵函数,
\[L_i^{facialExp}=-(y_i^{facialExp}log(p_i)+(1-y_i^{facialExp})(1-log(p_i)))\tag{3.5}\]其中$p_i$是输入经过网络后得到预测表情的概率值,$y_i^{facialExp}\in{0,1}$表示已标注的真实标签。
3.3 小结
本章节主要介绍了实现本课题具体使用的深度神经网络模型及其训练方法,通过一些现有的深度学习框架完成对上述理论模型的搭建,一个简单的人脸检测及人脸表情识别的深度学习模型就可以被成功建立了。在下一章,将具体介绍实现本课题所用的一些实验条件和方法。
4. 实验与测试
4.1 数据集
如上文提到的,实现人脸表情识别共需训练两个网络模型,MTCNN模型用来做人脸检测和人脸关键点回归,另一个AlexNet模型用来做人脸表情分类预测。对于训练MTCNN,需要使用两个数据集来进行模型训练,Wider Face数据集用来训练人脸二分类,CelebA数据集用来训练人脸边框回归(Bounding-Box Regression)以及人脸关键点回归。对于训练AlexNet,用于训练表情分类的数据集是Kaggle论坛上发布的fer2013人脸表情数据集。
WIDER FACE数据集是一个人脸面部检测基准数据集,共包含32,203张图像,其中共标记了393,703张人脸,这些人脸在尺度,姿态,遮挡方面都有很大的变化范围。Wider Face数据集的制作者来自于香港中文大学,其图像主要源自于公开数据集WIDER。
CelebA数据集是一个大规模人脸属性数据集,其中包含超过二十万个名人图像,每个图像都有40个属性注释,其中的人脸五点标记和人脸边框标记需要被利用到。此数据集中的图像涵盖了较大的姿势变化和杂乱背景。CelebA具有样式众多,数量众多且注释丰富的特点。CelebA数据集的制作者也来自于香港中文大学。
Fer2013数据集发布于Kaggle平台,是目前相对较大的人脸表情识别公开数据集。共包含35886张人脸表情图片,测试集图像有28708张,公共验证集图像和私有验证集图像各3589张,所有图片都是由固定尺寸为48×48的灰度图像,共包含7种表情(与上文所述相符,包含了中性),并且所属类别已被标注。官方发布的数据集的格式为csv格式,所以需先对其进行格式转换(此实验中使用的python中pandas库对csv文件进行的处理),转换成为可用的图像格式。
4.2 网络搭建及训练
4.2.1 实验环境
- 系统:Ubuntu 16.04LTS;
- GPU:TITAN X;
- 语言环境:Python2.7;
- 深度学习框架:Caffe;
- 所用依赖库包括:pycaffe、opencv、numpy、pandas、cPickle等。
4.2.2 网络搭建及训练
利用深度学习框架Caffe完成对所需网络的搭建和训练,搭建上述网络,搭建后caffe深度学习网络具体参数可参见附录,使用Caffe的原始是因为其对于简单网络的搭建很方便,且运算效率也很高。对于训练集和测试集,在MTCNN网络中,人脸边框回归任务对于训练集和验证集分别可以达到92.3%以及85%的回归率,对于人脸关键点定位达到91.3%和79%的准确率。然而对于人脸表情分类模块,对于验证集的准确率仅仅达到了63.5%识别率。对表情识别的识别率过低的原因进行分析,作者本人认为是因为人类表情过于复杂,对于一些微微的肌肉形变,计算机很难对其察觉,人类自己有时也很难对表情作出正确判断。
在向网络输入图像时(此处不单独讨论视频任务,视频只是将多张图片组合而成的图像流),需要对输入图像进行预处理,包括图像归一化处理以保证模型收敛的更快、图像尺寸处理(最长边限制在1000像素以内)以确保计算效率、。
4.3 算法测试
如图8和图9所示,分别对应该网络模型分别对静态图像和视频流任务的测试结果。对于具有相对完整人脸的图像(如图8上面两个测试结果),该模型可以很好的对其进行识别,但是对于图像中包含不完整人脸、肤色较深、姿势过偏的,该模型还是不能很好的对其进行检测,这也应证了第一章所说的在不受控的条件下在人脸检测任务中的难点所在。在GPU环境下,对于视频文件(如图9为240p,30fps视频文件)的测试,可以达到15fps左右,可以看出本算法还不完善,还不能达到实时的效果,在MTCNN原作论文中,作者的人脸检测和关键点回归模型可以达到99fps。
 图9 对于图像的测试结果
图9 对于图像的测试结果
 图10 对于视频的测试结果
图10 对于视频的测试结果
4.4 小结
本章节介绍了对于本文所用人脸检测以及人脸表情识别深度神经网络模型的实现和测试结果,不难看出,对于人脸表情识别网络,虽然在训练时对于验证集测试的准确率仅仅达到63.5%,但是在实际测试时,对于较明显人脸表情测试的准确率还是不错的。本模型目前较大的问题仍在运算效率上,仍不能满足工业级实时性的要求。
参考文献
Li H , Lin Z , Shen X , et al. A convolutional neural network cascade for face detection[C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2015. ↩ ↩2
Viola P A , Jones M J . Rapid Object Detection using a Boosted Cascade of Simple Features[C]// IEEE Computer Society Conference on Computer Vision & Pattern Recognition. IEEE, 2001. ↩
C. Zhang and Z. Zhang. A survey of recent advances in face detection. Technical Report MSR-TR-2010-66, 2010. ↩
徐琳琳, 张树美, 赵俊莉. 基于图像的面部表情识别方法综述[J]. 计算机应用, 2017(12):171-178+208. ↩
D, C, P,等. The Expression of Emotions in Man and Animals[J]. The American Journal of Psychology, 1981.用,2017,37(12):3509-3516+3546. ↩
Ekman P , Friesen W V , Ellsworth P C . Emotion in the Human Face[M]. Cambridge University Press ;, 1982. ↩
Y. l. Tian, T. Kanade, and J. F. Cohn, “Evaluation of Gabor-Wavelet-Based Facial Action Unit Recognition in Image Sequences of Increasing Complexity,” in Proceedings of the Fifth IEEE International Conference on Automatic Face and Gesture Recognition, pp. 229-234, 2002. ↩
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems. 2012: 1097-1105. ↩
Lecun Y , Bengio Y , Hinton G . Deep learning[J]. nature, 2015, 521(7553):436. ↩
Y-Lan Boureau, Jean Ponce, Yann LeCun. A Theoretical Analysis of Feature Pooling in Visual Recognition[C]// International Conference on Machine Learning. DBLP, 2010. ↩
Zhang K , Zhang Z , Li Z , et al. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks[J]. IEEE Signal Processing Letters, 2016, 23(10):1499-1503. ↩
Girshick, R., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for accurate object detection and semantic segmentation. In: CVPR (2014) ↩
Shelhamer E , Long J , Darrell T . Fully Convolutional Networks for Semantic Segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4):640-651. ↩
He K , Zhang X , Ren S , et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 37(9):1904-16. ↩